В отличие от интуитивных методов прогнозирования, рассмотренных в предыдущей главе, дальнейшее изучение методов прогнозирования посвящено изучению формальных методов. Название формальные методы они получили потому, что основаны на достаточно формализованных (точно описанных) действиях, которые необходимо выполнить для получения прогноза.
Задача прогнозирования по выборке возникает в том случае, когда имеются данные по нескольким объектам аналогичным объекту прогнозирования по своим свойствам и на основании этой информации необходимо спрогнозировать состояние искомого объекта прогнозирования. Второй вариант – имеются данные о состоянии объекта прогнозирования в прошлом и необходимо на их основании спрогнозировать его состояние в будущем. В первом случае говорят, что имеются перекрестные данные, во втором – временные.
В подавляющем большинстве случаев величины, которыми оперируют в экономике, непрерывно колеблются. Например, даже при неизменных объемах производства и ценах на ресурсы из-за неизбежных отклонений в производственных процессах колеблются затраты, от периода к периоду колеблются выручка, прибыль, любые параметры макроэкономики. Все это случайные или второе название стохастические величины (стохостикос — по-гречески означает угадывающий). С позиций прогнозирования случайная величина это такая величина очередное значение которой не возможно предсказать точно.
Случайные переменные обычно подразделяют на два вида:
непрерывная случайная величина – случайная величина которая может принимать любое значение из заданного диапазона (в пределе от ![]()
![]() до
до ![]() );
);
дискретная случайная величина — случайная величина которая может принимать любое значение из фиксированного набора допустимых значений (число детей в семье – целое положительное число, уровень инфляции обычно сообщается с точностью до десятых долей процента и т.д.). Практически любые величины округленные до определенной точности являются дискретными.
Все возможные значения случайной величины — как прошлые, так и будущие, как известные так и неизвестные — называют генеральной совокупностью случайной величины. Любая часть этой генеральной совокупности называется выборкой. В прогнозировании генеральная совокупность никогда на известна так как в противном случае нет самой задачи прогнозирования. Известна только выборка из генеральной совокупности, т.е. известны ![]()
![]() значений генеральной совокуп-ности по которым необходимо предсказать ее
значений генеральной совокуп-ности по которым необходимо предсказать ее ![]() ,
, ![]() , … значения. Поскольку по определению случайной величины ее очередное значение меняется при каждом своем появлении, то необходимо не только предсказать ее очередное значение, но и указать в каких пределах следует ожидать ее колебания. Иными словами помимо самого прогноза необходимо оценить его точность.
, … значения. Поскольку по определению случайной величины ее очередное значение меняется при каждом своем появлении, то необходимо не только предсказать ее очередное значение, но и указать в каких пределах следует ожидать ее колебания. Иными словами помимо самого прогноза необходимо оценить его точность.
Таким образом, в математической постановке задача прогнозирования по выборке выглядит следующим образом. Имеем выборку из генеральной совокупности мощностью ![]()
![]() . По этой выборке необходимо оценить параметры генеральной совокупности и на их основании осуществить прогноз очередного значения случайной величины и указать какую-то меру точности полученного прогноза.
. По этой выборке необходимо оценить параметры генеральной совокупности и на их основании осуществить прогноз очередного значения случайной величины и указать какую-то меру точности полученного прогноза.
Предварительный анализ данных.
Известно ![]()
![]() значений случайной величины Х –
значений случайной величины Х –![]() ,
, ![]() , …
, … ![]() . Для удобства последующего анализа эти значения обычно сортируют по возрастающей, в электронных таблицах эта операция выполняется практически мгновенно. В случае если выборка большая, а случайная величина дискретная, то в выборке может оказаться большое число повторяющихся значений, и в этом случае выборку удобнее представить в виде двух рядов чисел:
. Для удобства последующего анализа эти значения обычно сортируют по возрастающей, в электронных таблицах эта операция выполняется практически мгновенно. В случае если выборка большая, а случайная величина дискретная, то в выборке может оказаться большое число повторяющихся значений, и в этом случае выборку удобнее представить в виде двух рядов чисел:
![]()
![]() и
и ![]()
где: ![]()
![]() – значения случайной величины;
– значения случайной величины;
![]()
![]() – число повторений каждого i-го значения.
– число повторений каждого i-го значения.
Второй вариант представления выборки дискретной случайной величины – рассчитать вероятность появления i-го значения случайной величины по формуле:
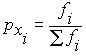 и представить выборку в виде
и представить выборку в виде ![]() ,
, ![]() .
.
Основной частью предварительного анализа данных является построение гистограммы случайной величины по данным выборки. Гистограмма – это столбчатая диаграмма по горизонтальной оси которой нанесены обычно равномерные интервалы случайной величины, а по вертикальной – число попаданий случайной величины в эти интервалы.
В случае если полученная гистограмма имеет более одной вершины (рис 5, а), то это является сигналом того, что исходные данные представляют собой выборку не одной случайной величины, а являются суммой двух выборок двух разных случайных величин. Например, вместо перекрестных данных одного и того же класса имеются данные об объектах принадлежащих двум разным классам, или данные о состоянии объекта прогнозирования в прошлом относятся к двум его разным состояниям – до каких либо структурных изменений и после этих изменений. Во всех подобных случаях в прогнозирование будет введена существенная ошибка, поскольку объект принадлежит к какому-то одному классу или находится в конкретном состоянии (после изменения) а не оба (до и после изменения). По этому при наличии у гистограммы более одной вершины исходные данные должны быть тщательно проанализированы на предмет удаления из них данных, не имеющих отношения к объекту прогнозирования.
Заслуживают тщательного внимания и выбросы на гистограмме (рис5, б), особенно если эти выбросы расположены на некотором расстоянии от основной фигуры гистограммы. Данные соответствующие выбросам полезно детально изучить так как они обычно сигнализируют о наличии сбоев в изучаемом процессе или иных отклонений от обычного хода дел, включая случаи злоупотреблений, воровства и т.д.
И наконец, внешний вид гистограммы позволяет приближенно судить о характере распределения случайной величины. В случае если гистограмма напоминает симметричную одновершинную фигуру, то дальнейшая работа по прогнозированию может быть выполнена в предположении, что случайная величина имеет нормальное распределение работы с которым наиболее проста в виду хорошей теоретической изученности этого распределения и разнообразности разработанных для него приемов и методов обработки. В случае если это не так (рис 5, в), то необходимо воспользоваться каким либо другим специальным распределением, что обычно усложняет задачу анализа.
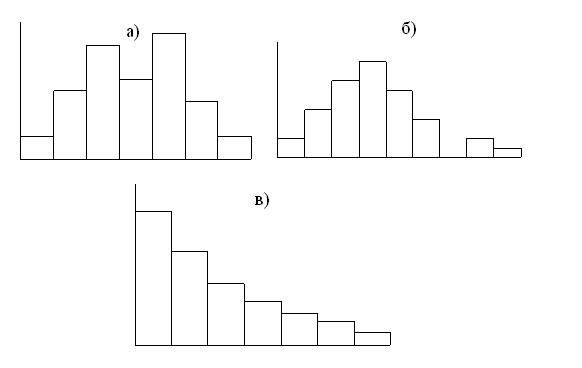
Рис 5. Гистограммы случайных величин.
Следует отметить, что визуальный анализ исходных данных по внешнему виду гистограммы является приближенным, так как, во-первых, внешний вид гистограммы может существенно изменяться при изменении числа интервалов на гистограмме, во-вторых, отсутствуют числовые критерии для диагностики того или иного предположения. Существуют более надежные статистические методы проверки обсуждавшихся выше предположений, но они требуют больших (обычно более 50 – 100 точек) выборок, что редко встречается в практике прогнозирования и специальных методов обработки. Визуальный анализ позволяет с минимальными затратами или получить результат или выявить те случаи когда требуются специальная статистическая обработка. По этому с учетом простоты построения гистограмм в электронных таблицах, следует считать, что он обязателен при построении прогноза.